
Liebes Forum,
ich hoffe mir kann jemand weiterhelfen, da es bei mir zeitlich sehr knapp ist und ich seit einigen Tagen nicht weiterkomme.
Ich sitze gerade an der empirischen Analyse zu meiner Masterarbeit. Mein Wunsch ist es den Effekt auf die Handelsaktivität in der französischen Finanztransaktionssteuer zu messen, die am 01. August eingeführt wurde. Dazu vergleiche ich im Rahmen einer Difference in Difference Regression die Entwicklung in französischen den Werten (Treatment Gruppe) mit der Entwicklung in Deutschland (Control Group) jeweils einen Monat vor und nach Einführung der FTS am 01. August 2012.
Dabei habe ich ein gepooltes Modell, kein Panel oder Ähnliches. Das Modell sieht wie folgt aus:
yi = b0 + b1 DummyAUG + b2 DummyFR + b3 DummyAUG*DummyFR + ei
Das Grundmodell besteht also nur aus drei Dummies, einem Dummy für den Monat August, einem Dummy für die französischen Werte und einem Interaktionsdummy, der genau der Diff-in-Diff Schätzer. Y ist das jeweils von mir gemessene Liquiditätsmaß.
Nun zum Problem: Ich habe 5-Minuten Beobachtungen für jeden deutschen und französischen Wert, und das über 45 Handelstage hinweg (Juli und August). D. h. ich habe eine hohe Autokorrelation, sowohl zeitlich betrachtet (time series correlation) als auch zwischen den Aktien (cross section autocorrelation).
Die Literatur bietet verschiedene Ansätze, von AR(1) über zeit- und querschnittsrobusten Standardfehlern (Prais-Winsten etc.), jedoch kann man diese, wie ich sehe, nur bei Panel-Regressionen, nicht bei dem von mir gepoolten / aggregierten Modell nutzen, wo ich alle 5-Minuten Beobachtungen für die 45 Tage und deutschen und franz. Unternehmen quasi "in einen Topf schmeiße."
Wenn ich also in STATA eine Zeitvariable kreeiren würde, um eine Regression mit Prais-Winsten AK-robusten SE durchzuführen, dann hätte ich bei meinem Modell falsche/fortlaufende Benennung der Zeitvariablen, so dass die AK-Korrektur bzw. Standardfehlerkorrektur nicht richtig wäre.
Daher meine Frage: Gibt es evtl. Autokorrelation-robuste Standardfehler, die man auch in gepoolten Modellen nutzen kann? Oder gibt es andere einfache Methoden dem AK-Problem zu begegnen? Mein Betreuer sagte, ich solle bspw. zur Eindämmung der AK Tages- und Uhrzeitdummies mit ins Modell nehmen, was ich noch machen werde, aber reicht das?
Gerne kann ich einen Beispieldatensatz schicken, damit es übersichtlicher wird. Wäre echt toll, wenn mir jemand helfen könnte, da ich den heutigen Samstag Abend sicher noch in der Bibliothek verbringen werde und für jede Hilfe dankbar bin.
Für den Datensatz einfach bitte eine Privatnachricht senden.
Grüße
Johnnybegood
Dringende Frage: Difference in Difference Regression
27 Beiträge
• Seite 1 von 3 • 1, 2, 3
Dringende Frage: Difference in Difference Regression
![]() von djan » Sa 27. Apr 2013, 18:44
von djan » Sa 27. Apr 2013, 18:44
- djan
- Beiträge: 15
- Registriert: Sa 27. Apr 2013, 18:24
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Dringende Frage: Difference in Difference Regression
![]() von daniel » Sa 27. Apr 2013, 21:05
von daniel » Sa 27. Apr 2013, 21:05
Hab das Problem nur überflogen, aber wenn es im Panledatenstz keines wäre, was spricht denn dagegen, die Daten als Panel zu deklarieren?
- daniel
- Beiträge: 1060
- Registriert: Sa 1. Okt 2011, 17:20
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Dringende Frage: Difference in Difference Regression
![]() von djan » Sa 27. Apr 2013, 21:29
von djan » Sa 27. Apr 2013, 21:29
Danke für die Antwort.
Wenn ich die Daten in ein Panel überführen würde, wüsste ich nicht mehr, wie man eine Difference in Difference Analyse durchführen sollte.
Diff-in-Diff arbeitet ja normalerweise mit gepoolten/aggregierten Daten.
Habe auch Papers gelesen, die bei DID Panelanalysen durchgeführt haben, ich selbst hab das nicht wirklich verstanden. Mein Betreuer meinte, er erwartet keine Panelanalyse von mir, das gepoolte Modell, so wie ich es aufgeschrieben habe reicht. Das Problem der Autokorrelation soll ich mit zusätzlichen Kontrollvariablen, vor allem Tages- und Uhrzeitvariablen versuchen einzuschränken. Auch hat er mir gesagt, soll ich versuchen in STATA Standardfehler zu nutzen, die AK-robust sind, aber diese finde ich eben nur für Panelanalysen, nicht für gepoolte Daten.
Das ist mein Dilemma. Wie kann ich also mit einem Datensatz, das nicht nach Uhrzeit- und Tag unterscheidet, und auch nicht nach Korrelation zwischen verschiedenen Unternehmen, dennoch eine halbwegs robuste Analyse durchführen?
Wenn ich die Daten in ein Panel überführen würde, wüsste ich nicht mehr, wie man eine Difference in Difference Analyse durchführen sollte.
Diff-in-Diff arbeitet ja normalerweise mit gepoolten/aggregierten Daten.
Habe auch Papers gelesen, die bei DID Panelanalysen durchgeführt haben, ich selbst hab das nicht wirklich verstanden. Mein Betreuer meinte, er erwartet keine Panelanalyse von mir, das gepoolte Modell, so wie ich es aufgeschrieben habe reicht. Das Problem der Autokorrelation soll ich mit zusätzlichen Kontrollvariablen, vor allem Tages- und Uhrzeitvariablen versuchen einzuschränken. Auch hat er mir gesagt, soll ich versuchen in STATA Standardfehler zu nutzen, die AK-robust sind, aber diese finde ich eben nur für Panelanalysen, nicht für gepoolte Daten.
Das ist mein Dilemma. Wie kann ich also mit einem Datensatz, das nicht nach Uhrzeit- und Tag unterscheidet, und auch nicht nach Korrelation zwischen verschiedenen Unternehmen, dennoch eine halbwegs robuste Analyse durchführen?
- djan
- Beiträge: 15
- Registriert: Sa 27. Apr 2013, 18:24
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Dringende Frage: Difference in Difference Regression
![]() von daniel » Sa 27. Apr 2013, 21:55
von daniel » Sa 27. Apr 2013, 21:55
Naja, wenn Du von einem einfachen -regress- nicht weg möchtest, dann hast Du die Möglichkeiten, die unter -help vce_option- angegeben sind. Wenn ich nur diese Möglichkeiten hätte, würde ich die Standradfehler wohl nach Land clustern.
- daniel
- Beiträge: 1060
- Registriert: Sa 1. Okt 2011, 17:20
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Dringende Frage: Difference in Difference Regression
![]() von djan » So 28. Apr 2013, 00:35
von djan » So 28. Apr 2013, 00:35
Eines hatte ich vergessen anzugeben. Ich habe meine 30 deutschen Aktien (Dax 30) und 40 franz. Aktien (CAC40) in 4 Klassen nach Marktkapitalisierung eingeteilt und führe die DID-Regressionen für jede Klasse durch. Kann ich also in jeder Klasse bzw. bei jeder Regression die SE nach deutschen und französischen Werten clustern, wie du es angemerkt hast?
Wie gut grenze ich die Autokorrelation ein, wenn ich neben dem Monatsdumm des DiD Grundmodells auch Tages- bzw. Uhrzeitdummies als Kontrollvariablen mit in die Regression aufnehme?
Danke für deine Hilfe. Grüße
johnnybegood
Wie gut grenze ich die Autokorrelation ein, wenn ich neben dem Monatsdumm des DiD Grundmodells auch Tages- bzw. Uhrzeitdummies als Kontrollvariablen mit in die Regression aufnehme?
Danke für deine Hilfe. Grüße
johnnybegood
- djan
- Beiträge: 15
- Registriert: Sa 27. Apr 2013, 18:24
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Dringende Frage: Difference in Difference Regression
![]() von daniel » So 28. Apr 2013, 11:07
von daniel » So 28. Apr 2013, 11:07
Ich denke, wenn Du in jeder Regression nach der "höchsten" Klasse (hier: Landesebene) clusterst, machst Du nichts verkehrt.
Der Vorschlag zur Kontrolle von Zeit- und Unternehmensdummies verwirrt mich ein wenig. Klar solltest Du das kontrolieren, um den allgemeinen Trend sowie Unternehmenspezifische unbeobachtete, zeitkonstante Heterogenität in den Griff zu bekommen. Diese Maßnahme führt zu "besseren" Punktschätzern -- mir ist allerding nicht wirklich klar, wie Kontrollvariablen die Autokorrelation der Standardfehler beeinflussen.
Bestenfalls kann ich mir vorstellen, dass zeitversetze Variablen helfen können. Also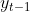 oder
oder 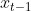 das Problem verringern können. Allerdings wäre ich damit vorsichtig, weil mir noch nicht ganz klar ist, unter welchen Umständen, diese Modelle zu verzerrten Schätzern führen.
das Problem verringern können. Allerdings wäre ich damit vorsichtig, weil mir noch nicht ganz klar ist, unter welchen Umständen, diese Modelle zu verzerrten Schätzern führen.
Der Vorschlag zur Kontrolle von Zeit- und Unternehmensdummies verwirrt mich ein wenig. Klar solltest Du das kontrolieren, um den allgemeinen Trend sowie Unternehmenspezifische unbeobachtete, zeitkonstante Heterogenität in den Griff zu bekommen. Diese Maßnahme führt zu "besseren" Punktschätzern -- mir ist allerding nicht wirklich klar, wie Kontrollvariablen die Autokorrelation der Standardfehler beeinflussen.
Bestenfalls kann ich mir vorstellen, dass zeitversetze Variablen helfen können. Also
- daniel
- Beiträge: 1060
- Registriert: Sa 1. Okt 2011, 17:20
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Dringende Frage: Difference in Difference Regression
![]() von djan » So 28. Apr 2013, 14:37
von djan » So 28. Apr 2013, 14:37
Hi Daniel,
ich habe die Help-Option gelesen, verstehe denn VCE-Befehl jedoch nicht ganz.
Vorher will ich Dir aber nochmal kurz darstellen, wie ich meine Analyse durchzuführen plane:
Für jede der vier Klassen nach Marktkapitalisierung (in denen ca. 5 deutsche und 6 französische Aktien enthalten sind, mit Beobachtungen für Juli und August - ca. 4500 Beobachtungen je Unternehmen, da 5 Minuten Daten) soll folgende dreistufige Analyse durchgeführt werden:
1. DID-Grundmodell: y = b0 + b1 Augustdummy + b2 *Frankreichdummy + b3 * Augustdummy*Frankreichdummy
2. Obiges Modell zzgl. 3-4 metrischen Kontrollvariablen
3. 1+2 zzgl. Tagesdummies, um zu schauen, an welchen Tagen der Effekt im Vgl. zu den anderen Tagen überdurchschnittlich groß oder klein war.
Wenn STATA länderspezifisch clustern soll, dann habe ich ja zwei Cluster (deutsche und franz. Werte). Kann ich STATA sagen, dass also nach der Dummyvariable geclustert werden soll?
Noch eine kurze theoretische Frage zur Anpassung der Standardfehler mithilfe der Clusterung: Soweit ich das verstehe, beschränken wir durch die Clusterung die innerdeutsche bzw. innerfranz. Korrelation in den Fehlertermen, aber nicht mögliche Korrelationen zw. Deutschland und Frankreich und auch keine Korrelationen über die Zeit (die bei meinen 5 Minuten Daten sicher vorliegen), d. h. kontrolierren also nur dafür, dass Entwicklungen im einen franz. Wert mit dem anderen franz. Wert (analog für deutsche Werte) korrelieren, oder?
ich habe die Help-Option gelesen, verstehe denn VCE-Befehl jedoch nicht ganz.
Vorher will ich Dir aber nochmal kurz darstellen, wie ich meine Analyse durchzuführen plane:
Für jede der vier Klassen nach Marktkapitalisierung (in denen ca. 5 deutsche und 6 französische Aktien enthalten sind, mit Beobachtungen für Juli und August - ca. 4500 Beobachtungen je Unternehmen, da 5 Minuten Daten) soll folgende dreistufige Analyse durchgeführt werden:
1. DID-Grundmodell: y = b0 + b1 Augustdummy + b2 *Frankreichdummy + b3 * Augustdummy*Frankreichdummy
2. Obiges Modell zzgl. 3-4 metrischen Kontrollvariablen
3. 1+2 zzgl. Tagesdummies, um zu schauen, an welchen Tagen der Effekt im Vgl. zu den anderen Tagen überdurchschnittlich groß oder klein war.
Wenn STATA länderspezifisch clustern soll, dann habe ich ja zwei Cluster (deutsche und franz. Werte). Kann ich STATA sagen, dass also nach der Dummyvariable geclustert werden soll?
Noch eine kurze theoretische Frage zur Anpassung der Standardfehler mithilfe der Clusterung: Soweit ich das verstehe, beschränken wir durch die Clusterung die innerdeutsche bzw. innerfranz. Korrelation in den Fehlertermen, aber nicht mögliche Korrelationen zw. Deutschland und Frankreich und auch keine Korrelationen über die Zeit (die bei meinen 5 Minuten Daten sicher vorliegen), d. h. kontrolierren also nur dafür, dass Entwicklungen im einen franz. Wert mit dem anderen franz. Wert (analog für deutsche Werte) korrelieren, oder?
- djan
- Beiträge: 15
- Registriert: Sa 27. Apr 2013, 18:24
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Dringende Frage: Difference in Difference Regression
![]() von daniel » So 28. Apr 2013, 15:34
von daniel » So 28. Apr 2013, 15:34
Wenn STATA länderspezifisch clustern soll, dann habe ich ja zwei Cluster (deutsche und franz. Werte). Kann ich STATA sagen, dass also nach der Dummyvariable geclustert werden soll?
Genau. Angenommen Deine Indikatorvariable heißt germ (1 = deutschland 0 = Frankreich), dann tippst Du
- Code: Alles auswählen
reg y x ,vce(cluster germ)
Soweit ich das verstehe, beschränken wir durch die Clusterung die innerdeutsche bzw. innerfranz. Korrelation in den Fehlertermen, aber nicht mögliche Korrelationen zw. Deutschland und Frankreich und auch keine Korrelationen über die Zeit
Teils, teils. Da den Fehlern innerhalb von Deutschland und Frankreich erlaubst, korreliert zu sein, wird damit m.E. zumindest auch die zeitliche Korrelation innerhalb der Länder abgedeckt. Ich erinnere mich an einen workshop, bei dem über zwei-stufiges clustern gesprochen wurde, und wie man das umsetzen könnte. Leider erinnere ich weder, wann genau das theoretisch nötig wäre, noch wie man es umsetzen könnte.
Eine Korrelation der Fehler zwischen den beiden Ländern scheint in der Tat problematisch, aber wenn Du nun mal Panel-/Zeitreiehndaten partout nicht mit den dazu geeigneten Modellen auswerten willst, musst Du wohl oder überl (mögl. sehr starke) Kompromisse eingehen. Es hat schon einen Grund, weshalb spezielle Modelle für solche Situationen entwickelt wurden -- was nicht bedeuten soll, dass diese Modelle trivial umzusetzen sind. Ich müsset mich da selbst wieder genauer einlesen, aber ich denke, Fakt ist, mit eineer einfachen gepoolten Regression wirst Du die Probleme nicht vollständig in den Griff bekommen. Ich würde ein paar Sensitivitätsanalysen fahren und schauen, welche Spezifikation welchen Einfluss auf meine substantiellen Schlussfolgerungen hat.
- daniel
- Beiträge: 1060
- Registriert: Sa 1. Okt 2011, 17:20
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Dringende Frage: Difference in Difference Regression
![]() von djan » So 28. Apr 2013, 16:07
von djan » So 28. Apr 2013, 16:07
Hi Daniel,
danke nochmal. Hab das so umgesetzt, jedoch passiert etwas, was ich nicht ganz nachvollziehen kann:
Wenn ich das Grundmodell (nur mit den Dummies) schätze, ergibt eine Clusterung sogar noch kleinere Standardfehler für die Koeffizienten, als dies vorher der Fall war.
Füge ich hingegen als zusätzliche erklärende Variable zum Grundmodell noch eine metrische Variable mit ein und schätze das Modell dann einmal geclustert, einmal ohne Clusterung, erhalte ich das erwartete Ergebnis. Die Clusterung liefert höhere Standardfehler, d. h. weniger Signifikanz.
Darf man also in eine Regression mit reinen Dummies keine Clusterung durchführen? Hat das also was mit den Annahmen bei Dummy-Regressionen zu tun?
Habe die Regressionsergebnisse in ein Excel Sheet gepackt und für Dich hochgeladen. Hoffe du siehst hier eine Lösung.
danke nochmal. Hab das so umgesetzt, jedoch passiert etwas, was ich nicht ganz nachvollziehen kann:
Wenn ich das Grundmodell (nur mit den Dummies) schätze, ergibt eine Clusterung sogar noch kleinere Standardfehler für die Koeffizienten, als dies vorher der Fall war.
Füge ich hingegen als zusätzliche erklärende Variable zum Grundmodell noch eine metrische Variable mit ein und schätze das Modell dann einmal geclustert, einmal ohne Clusterung, erhalte ich das erwartete Ergebnis. Die Clusterung liefert höhere Standardfehler, d. h. weniger Signifikanz.
Darf man also in eine Regression mit reinen Dummies keine Clusterung durchführen? Hat das also was mit den Annahmen bei Dummy-Regressionen zu tun?
Habe die Regressionsergebnisse in ein Excel Sheet gepackt und für Dich hochgeladen. Hoffe du siehst hier eine Lösung.
- Dateianhänge
-
 Clusterungsbeispiel.xlsx
Clusterungsbeispiel.xlsx- (101 KiB) 385-mal heruntergeladen
- djan
- Beiträge: 15
- Registriert: Sa 27. Apr 2013, 18:24
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
Re: Dringende Frage: Difference in Difference Regression
![]() von daniel » So 28. Apr 2013, 16:19
von daniel » So 28. Apr 2013, 16:19
Hab nur etwa 2 Sekunden draufgeschaut, aber ich sehe kein Modell mit "OLS" Standardfehlern als Vergleich. Du verwendest einmal -robust-e Standradfehler (Huber-White) und einmal geclusterte Standradfehler. Wer soll da theoretisch sagen können, welcher Fehler kleiner und welcher größer ist? Beide sind ineffizient.
- daniel
- Beiträge: 1060
- Registriert: Sa 1. Okt 2011, 17:20
- Danke gegeben: 0
- Danke bekommen: 0 mal in 0 Post
27 Beiträge
• Seite 1 von 3 • 1, 2, 3
Wer ist online?
Mitglieder in diesem Forum: Google [Bot] und 1 Gast
Powered by phpBB
Supported by

Stata is a registered trademark of StataCorp LP registered with the World Intellectual Property Organization, registration number 1058744 and this trademark is used with the expressed permission of StataCorp LP. The web site, www.stata-forum.de, is not affiliated with StataCorp LP and the content of the site is developed independently from StataCorp LP. For additional information regarding the Stata product, visit DPC Software or stata.com.
Supported by
Stata is a registered trademark of StataCorp LP registered with the World Intellectual Property Organization, registration number 1058744 and this trademark is used with the expressed permission of StataCorp LP. The web site, www.stata-forum.de, is not affiliated with StataCorp LP and the content of the site is developed independently from StataCorp LP. For additional information regarding the Stata product, visit DPC Software or stata.com.